从valine迁移到waline及数据导入
登录leancloud,突然发现停服公告,valine的数据一直存放在这里,于是把留言系统从valine迁移到waline。本文记录了迁移过程。
waline
项目地址:walinejs/waline
有多种部署方式,这里采用docker本地部署。
飞牛上部署
mkdir -p /vol1/1000/docker/waline/data
nano /vol1/1000/docker/waline/docker-compose.yml
services:
waline:
container_name: waline
image: lizheming/waline:latest
restart: always
ports:
- 8360:8360
volumes:
- ./data:/app/data
environment:
TZ: 'Asia/Shanghai'
SQLITE_PATH: '/app/data'
JWT_TOKEN: '12345'
SITE_NAME: 'xxxx'
SITE_URL: 'https://xxx.com'
SECURE_DOMAINS: 'xxx.com'
AUTHOR_EMAIL: 'a@a.com'
从浏览器进入飞牛,点开Docker,Compose,新增项目,输入waline,定位到刚才的目录,确认,构建项目。下载https://github.com/walinejs/waline/blob/main/assets/waline.sqlite,保存到/vol1/1000/docker/waline/data,重新构建waline。
从内网ip:8360可访问。把ip:8360用frp反代到公网。在hexo butterfly的配置文件中启用waline,填入反代的地址。重新构建hexo就启用了waline。
数据库迁移
登录leancloud,打开valine应用,左侧点击导入导出,
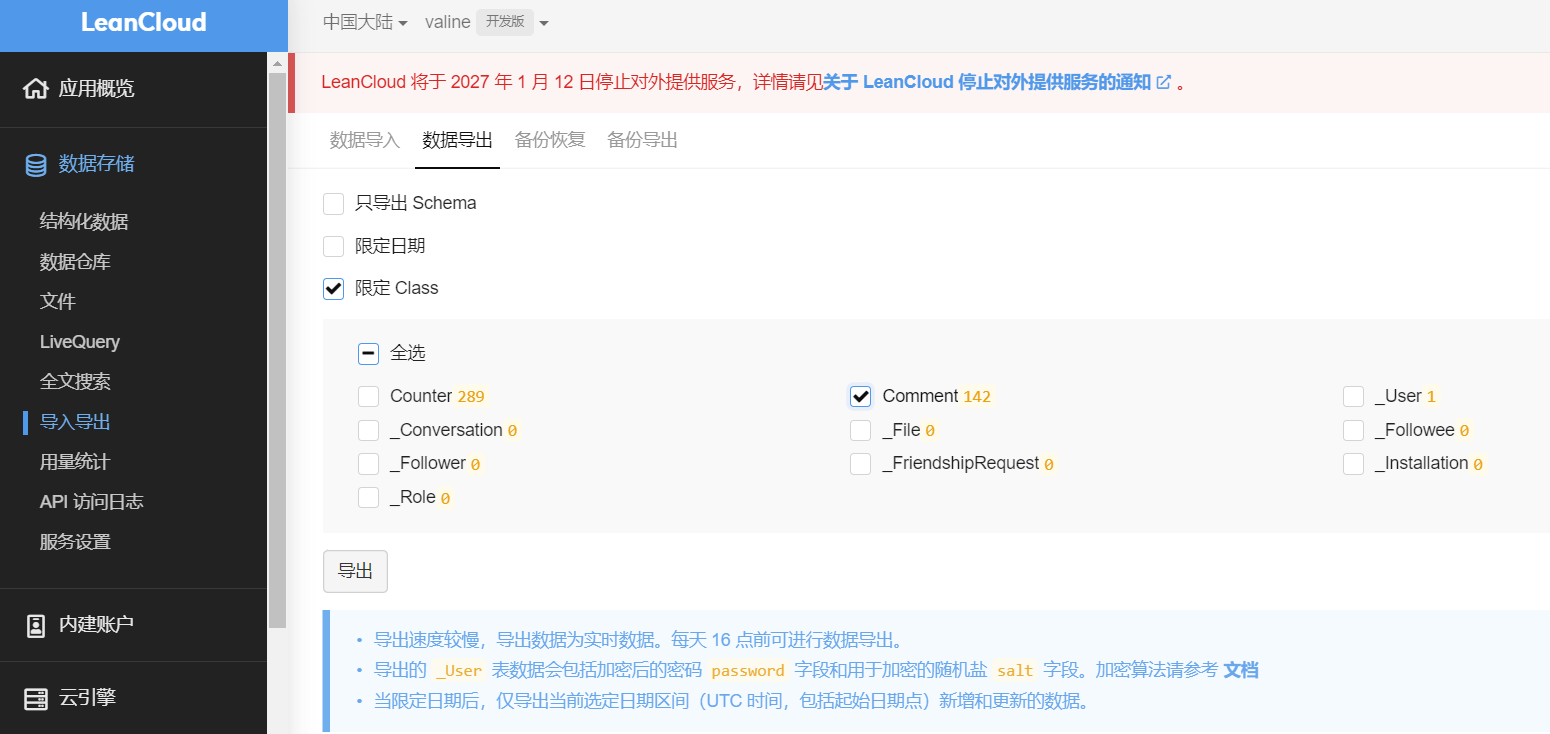
导出的文件会发送到邮箱,下载到本地,解压得到Comment.0.jsonl。
打开waline官方提供的数据迁移助手,
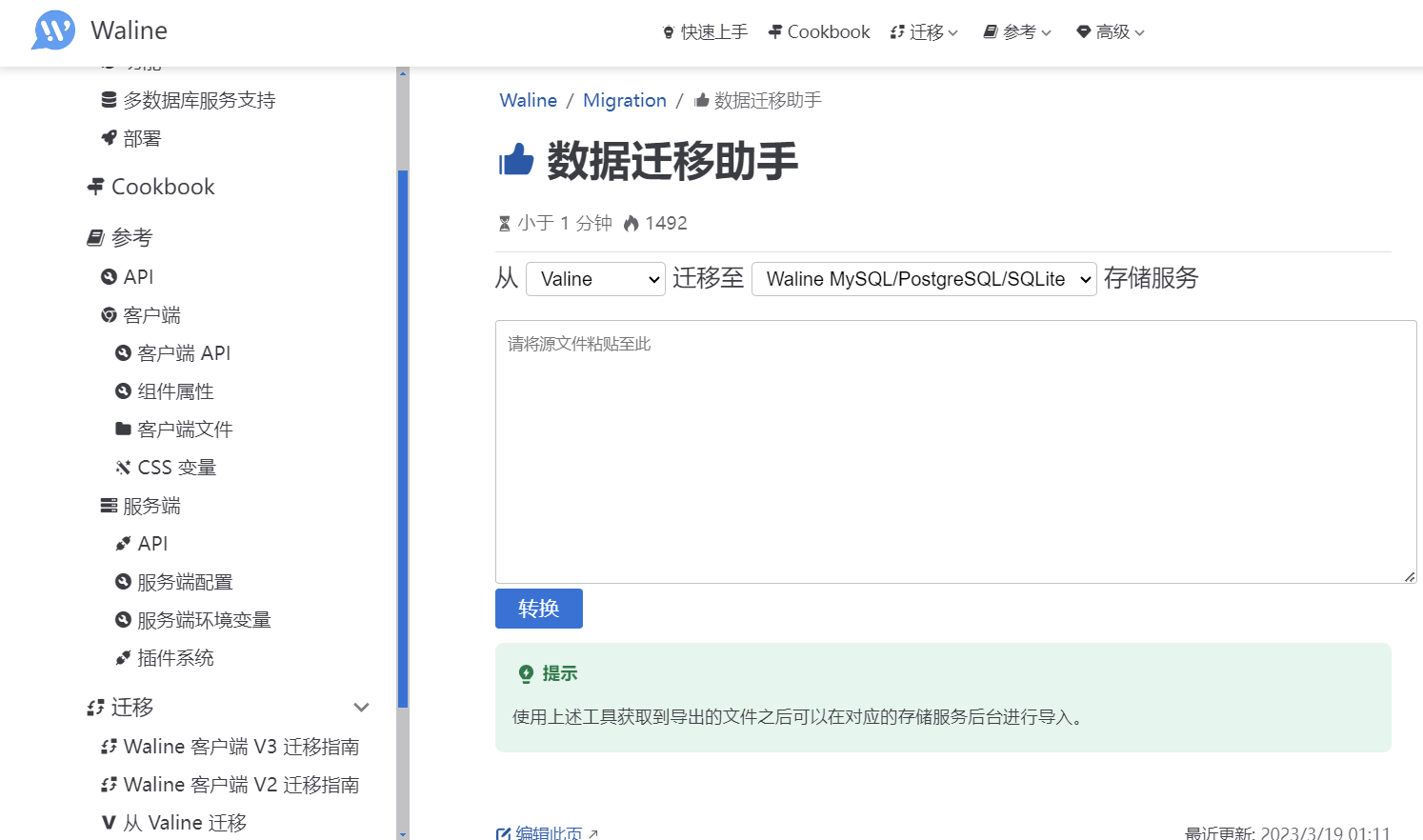
打开Comment.0.jsonl,把内容复制到文本框,删除第一行,点转换,得到一个output.csv。
下载SQLite Expert Professional,安装(可试用40天),用软件打开waline.sqlite,点击菜单栏Import/Export,Import txt file
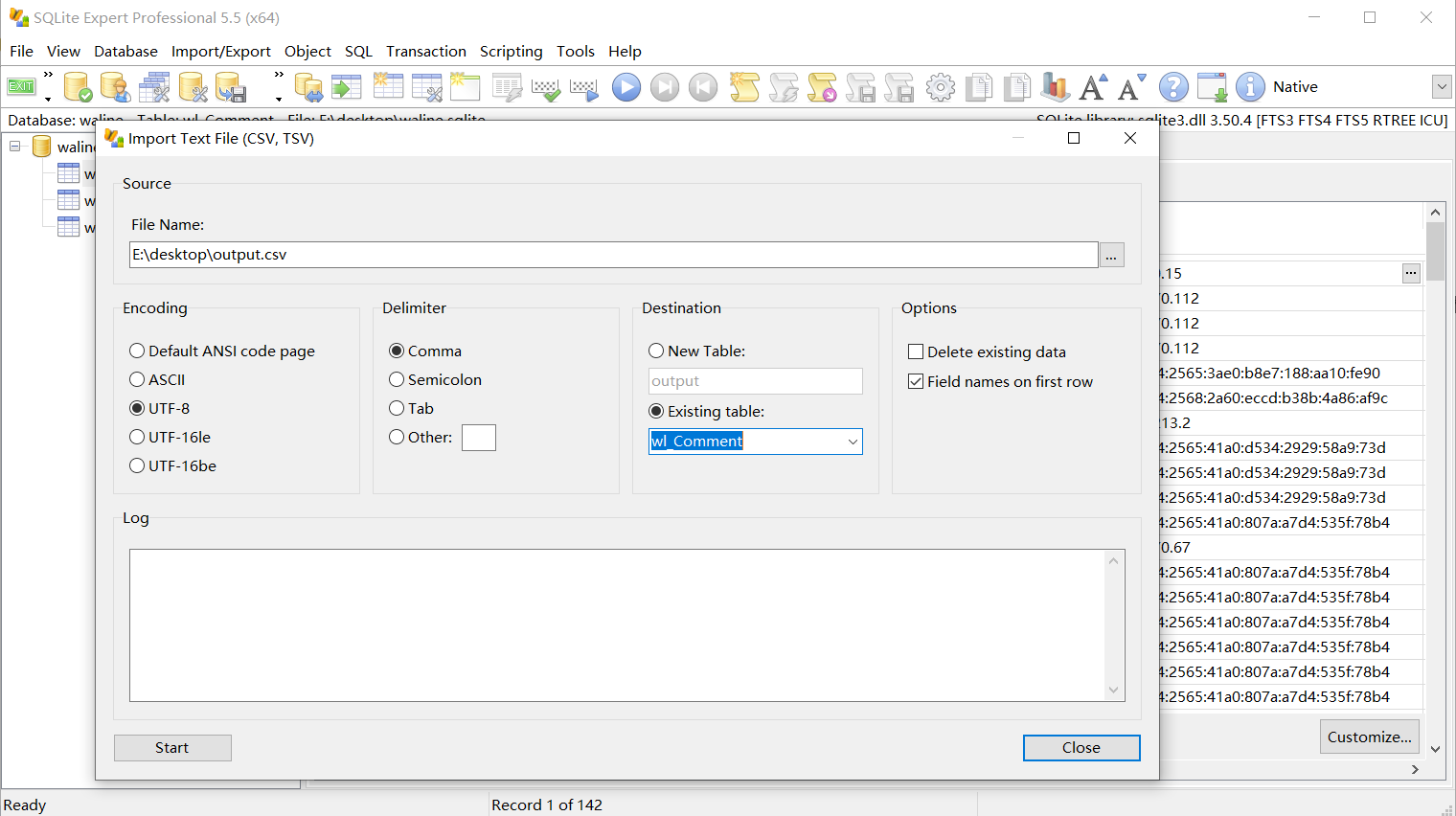
点start导入数据,之后关闭数据库,把waline.sqlite文件保存到/vol1/1000/docker/waline/data,重新构建docker。打开网站,可以看到已有的留言已导入。
csv导入到sqlite数据库的python脚本:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import sqlite3
import csv
import os
import argparse
from pathlib import Path
def detect_delimiter(file_path, sample_size=5):
"""自动检测CSV文件的分隔符"""
with open(file_path, 'r', encoding='utf-8') as f:
sample = ''.join([f.readline() for _ in range(sample_size)])
delimiters = [',', ';', '\t', '|']
delimiter_counts = {d: sample.count(d) for d in delimiters}
return max(delimiter_counts, key=delimiter_counts.get)
def detect_encoding(file_path):
"""尝试检测文件编码(简化版)"""
encodings = ['utf-8', 'gbk', 'gb2312', 'utf-16', 'latin-1']
for encoding in encodings:
try:
with open(file_path, 'r', encoding=encoding) as f:
f.read()
return encoding
except UnicodeDecodeError:
continue
return 'utf-8'
def infer_sqlite_type(value):
"""根据值推断SQLite数据类型"""
if value is None or value == '':
return 'TEXT'
try:
int(value)
return 'INTEGER'
except ValueError:
pass
try:
float(value)
return 'REAL'
except ValueError:
pass
return 'TEXT'
def csv_to_sqlite(csv_file, db_file, table_name=None,
delimiter=None, encoding=None,
has_header=True, if_exists='replace'):
"""
将CSV文件导入到SQLite数据库
参数:
csv_file: CSV文件路径
db_file: SQLite数据库文件路径
table_name: 表名(默认使用CSV文件名)
delimiter: 分隔符(None则自动检测)
encoding: 编码(None则自动检测)
has_header: CSV是否有表头
if_exists: 表已存在时的处理方式 ('replace', 'append', 'fail')
"""
# 自动检测分隔符
if delimiter is None:
delimiter = detect_delimiter(csv_file)
print(f"检测到分隔符: '{delimiter}'")
# 自动检测编码
if encoding is None:
encoding = detect_encoding(csv_file)
print(f"检测到编码: {encoding}")
# 表名默认使用CSV文件名
if table_name is None:
table_name = Path(csv_file).stem
# 清理表名(SQLite表名不能以数字开头等)
table_name = ''.join(c if c.isalnum() else '_' for c in table_name)
if table_name[0].isdigit():
table_name = '_' + table_name
print(f"目标表名: {table_name}")
# 读取CSV文件
rows = []
with open(csv_file, 'r', encoding=encoding) as f:
if has_header:
reader = csv.reader(f, delimiter=delimiter)
header = next(reader)
# 清理列名
columns = [col.strip().replace(' ', '_') for col in header]
rows = list(reader)
else:
reader = csv.reader(f, delimiter=delimiter)
rows = list(reader)
if rows:
columns = [f'col_{i}' for i in range(len(rows[0]))]
else:
columns = []
if not rows:
print("CSV文件为空")
return
# 连接数据库
conn = sqlite3.connect(db_file)
cursor = conn.cursor()
# 处理表存在的情况
cursor.execute(f"SELECT name FROM sqlite_master WHERE type='table' AND name='{table_name}'")
table_exists = cursor.fetchone() is not None
if table_exists:
if if_exists == 'fail':
raise ValueError(f"表 {table_name} 已存在,且 if_exists='fail'")
elif if_exists == 'replace':
cursor.execute(f"DROP TABLE IF EXISTS {table_name}")
print(f"删除已存在的表: {table_name}")
table_exists = False
# 创建表(如果需要)
if not table_exists:
# 推断列的数据类型
column_types = []
for col_idx in range(len(columns)):
col_values = [row[col_idx] if col_idx < len(row) else '' for row in rows[:100]]
non_empty = [v for v in col_values if v.strip()]
if non_empty:
col_type = infer_sqlite_type(non_empty[0])
else:
col_type = 'TEXT'
column_types.append(col_type)
# 创建表的SQL语句
columns_sql = ', '.join([f'"{columns[i]}" {column_types[i]}' for i in range(len(columns))])
create_sql = f'CREATE TABLE {table_name} ({columns_sql})'
cursor.execute(create_sql)
print(f"创建表: {table_name}")
# 准备插入语句
placeholders = ','.join(['?' for _ in columns])
insert_sql = f'INSERT INTO {table_name} VALUES ({placeholders})'
# 执行批量插入
batch_size = 1000
total_rows = len(rows)
inserted = 0
for i in range(0, total_rows, batch_size):
batch = rows[i:i+batch_size]
# 确保每行的列数一致
batch_data = []
for row in batch:
# 补齐缺少的列
if len(row) < len(columns):
row = row + [''] * (len(columns) - len(row))
# 截断多余的列
elif len(row) > len(columns):
row = row[:len(columns)]
batch_data.append(row)
cursor.executemany(insert_sql, batch_data)
conn.commit()
inserted += len(batch)
print(f"已导入: {inserted}/{total_rows} 行")
# 获取导入后的行数
cursor.execute(f"SELECT COUNT(*) FROM {table_name}")
final_count = cursor.fetchone()[0]
conn.close()
print(f"导入完成!表 '{table_name}' 共有 {final_count} 行记录")
return final_count
def main():
parser = argparse.ArgumentParser(description='将CSV文件导入SQLite数据库')
parser.add_argument('csv_file', help='CSV文件路径')
parser.add_argument('-d', '--db', default='database.sqlite',
help='SQLite数据库文件路径(默认: database.sqlite)')
parser.add_argument('-t', '--table', help='表名(默认使用CSV文件名)')
parser.add_argument('--delimiter', help='CSV分隔符(默认自动检测)')
parser.add_argument('--encoding', help='文件编码(默认自动检测)')
parser.add_argument('--no-header', action='store_false', dest='header',
help='CSV文件没有表头')
parser.add_argument('--if-exists', choices=['replace', 'append', 'fail'],
default='replace', help='表已存在时的处理方式(默认: replace)')
args = parser.parse_args()
try:
csv_to_sqlite(
csv_file=args.csv_file,
db_file=args.db,
table_name=args.table,
delimiter=args.delimiter,
encoding=args.encoding,
has_header=args.header,
if_exists=args.if_exists
)
except Exception as e:
print(f"错误: {e}")
return 1
return 0
if __name__ == '__main__':
exit(main())
保存为csv_to_sqlite.py
执行python csv_to_sqlite.py output.csv -d waline.sqlite -t wl_Comment
留言管理
官方说明注册的第一个用户是管理员,可管理留言,但目前无法注册,无论docker-compose中如何设置环境变量,始终显示403: Forbidden。
已解决注册问题,docker-compose文件中环境变量SECURE_DOMAINS需加入waline服务器地址,用逗号和网站地址分隔即可。

邮件服务
增加以下服务器变量:
SMTP_SERVICE: '163'
SMTP_USER: 'xxx@163.com'
SMTP_PASS: '******WABHMSHGIT'
smtp_pass对应邮箱密码或授权码。支持的邮件服务商在这里

用户注册和评论的邮件通知都会用到邮件服务。配置邮件服务相关变量后,用户注册会增加邮箱验证码确认相关的操作,用来防止恶意的注册。
改变服务器变量需重新构建waline。
参考:
https://waline.js.org/reference/server/env.html
头像服务
服务端中环境变量 GRAVATAR_STR 指定了获取头像的地址。
GRAVATAR_STR: https://seccdn.libravatar.org/avatar/{{mail\|md5}}
可用替代:
https://cravatar.cn/avatar/
https://cn.cravatar.com/avatar/
可加?d=指定头像
mp,monsterid等。
参考:
https://blog.uuanqin.top/p/1d248fa3/